
프로젝트 개요
Lending Club 대출 데이터를 활용하여 사회 초년생의 대출 상환 여부를 예측하는 머신러닝 모델을 구축했습니다.
사회 초년생 집단을 기준으로 데이터를 필터링하고 전처리 및 피처 엔지니어링을 수행한 뒤
Logistic Regression과 Random Forest 모델을 학습하여 대출 상환 예측 성능을 비교 분석했습니다.
사용 기술
Data Analysis
- Python, Pandas
Machine Learning
- Scikit-learn, Logistic Regression, Random Forest
Data Processing
- Feature Engineering, StandardScaler, One-Hot Encoding, VIF 기반 다중공선성 검토
주요 역할
데이터셋 구성
- Kaggle Lending Club 대출 데이터셋 활용
- 총 151개 컬럼 / 약 226만 건 데이터 분석
loan_status를 기준으로 이진 분류 문제 정의- 근속기간 5년 이하 조건을 적용하여 사회 초년생 집단 필터링
데이터 전처리 및 피처 엔지니어링
- 결측치 비율 30% 이상 컬럼 제거
- VIF 계산을 통해 다중공선성 검토
fico_range_low,fico_range_high평균값을 활용한 fico_score 변수 생성- 날짜형 데이터를 연도 기준 정수형으로 변환
- 범주형 변수 인코딩 및 수치형 변수 스케일링 수행
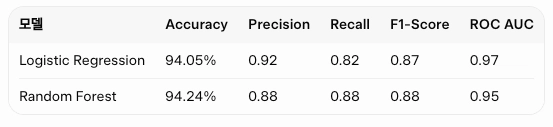
머신러닝 모델 학습 및 평가
- Logistic Regression 모델 학습
- Random Forest 모델 학습
- Accuracy, Precision, Recall, F1-score, ROC AUC 기준 성능 평가
문제 해결 및 개선 경험
대출 상태 데이터 정의 문제
원본 Lending Club 데이터에는 다양한 loan_status 값이 포함되어 있어
대출 상환 여부를 명확히 예측하기 위한 학습 데이터 구성에 어려움이 있었습니다.
이를 해결하기 위해 Fully Paid와 Charged Off 상태만 선택하여
대출 상환 여부를 이진 분류 문제로 재정의했습니다.
이를 통해 모델 학습에 적합한 데이터셋을 구성할 수 있었습니다.
결측치가 많은 컬럼 처리 문제
일부 변수는 결측치 비율이 높아 그대로 사용할 경우
데이터 신뢰성과 모델 성능에 부정적인 영향을 줄 수 있었습니다.
결측치 비율이 30% 이상인 컬럼을 제거하여
데이터 품질을 개선하고 분석 효율성을 높였습니다.
다중공선성 문제
수치형 변수 간 높은 상관관계가 존재할 경우
모델 계수의 불안정성과 해석 어려움이 발생할 수 있었습니다.
이를 해결하기 위해 VIF(Variance Inflation Factor)를 계산하여 다중공선성을 검토하고
상관관계가 높은 변수는 제거하거나 통합했습니다.
예를 들어 fico_range_low와 fico_range_high를 평균값으로 통합하여
fico_score 변수로 재구성했습니다.
모델 과적합 가능성 검토
모델 평가 과정에서 일부 지표가 0.99 수준으로 높게 나타나 과적합 가능성을 확인했습니다.
이를 해결하기 위해
- 변수 선택 과정 수행
- 단일 지표가 아닌 Precision / Recall / F1 / ROC AUC를 함께 확인하여 모델 성능을 다각도로 검증했습니다.
프로젝트 결과
- 대규모 금융 데이터를 활용한 대출 상환 예측 모델 구축
- 데이터 전처리 및 피처 엔지니어링을 통한 분석 데이터셋 구성 경험
- Logistic Regression과 Random Forest 모델 성능 비교 분석 수행
프로젝트 회고
대규모 금융 데이터를 분석하면서
모델 학습 이전의 데이터 전처리 과정이 모델 성능에 큰 영향을 준다는 점을 경험했습니다.
특히 사회 초년생이라는 특정 집단을 정의하고 분석 데이터를 구성하는 과정에서
도메인에 맞는 데이터 필터링과 변수 설계의 중요성을 확인할 수 있었습니다.